

Wichtigste Erkenntnisse
Die Wayback Machine ist ein kostenloses Online-Archiv mit über 735 Milliarden gespeicherten Webseiten seit 1996
Sie ermöglicht das Abrufen historischer Versionen von Websites über archive.org/web durch einfache URL-Eingabe
Das Tool ist unverzichtbar für SEO-Analysen, Content-Wiederherstellung und rechtliche Beweissicherung
Webseitenbetreiber können ihre Inhalte über robots.txt-Anweisungen von der Archivierung ausschließen
Als Teil des gemeinnützigen Internet Archive trägt sie zur Bewahrung des digitalen Kulturerbes bei
Das Internet vergisst nie – zumindest nicht mit der Wayback Machine. Während Webseiten verschwinden, sich verändern oder komplett neu gestaltet werden, bewahrt dieses außergewöhnliche Tool seit über 25 Jahren das digitale Gedächtnis unserer Online-Welt. Mit mehr als 735 Milliarden archivierten Seiten ist die Wayback Machine zur unverzichtbaren Ressource für online Recherchen, Content-Wiederherstellung und digitale Forensik geworden.
Was ist die Wayback Machine?
Die Wayback Machine ist das Flaggschiff-Tool des Internet Archive, einer non Profit Organisation mit Sitz in San Francisco. Sie funktioniert als digitale Zeitmaschine, die es Nutzern ermöglicht, historische Versionen von Webseiten zu betrachten, wie sie zu verschiedenen Zeitpunkten erschienen sind. Das Tool archiviert kontinuierlich Inhalte aus dem World Wide Web und macht sie über die intuitive Benutzeroberfläche auf web.archive.org zugänglich.
Gegründet wurde das Projekt 1996 von Brewster Kahle, einem visionären Informatiker und Gründer des Internet Archive. Kahles Ziel war es, universellen Zugang zu menschlichem Wissen zu schaffen und das schnelllebige Internet für zukünftige Generationen zu bewahren. Der Name “Wayback Machine” stammt aus der Cartoon-Serie “The Adventures of Rocky and Bullwinkle”, in der eine Zeitmaschine namens “WABAC” Zeitreisen ermöglichte.
Das Internet Archive speichert diese gewaltigen Datenmengen in seinen Rechenzentren in San Francisco und verfügt über mehr als 40 Petabyte Speicherkapazität. Die Collections umfassen nicht nur Webseiten, sondern auch Bücher, Videos, Audiodateien und Software. Das Projekt wird durch spenden finanziert und bietet kostenfreien Zugang für nutzer weltweit.
Die Wayback Machine ist über archive.org erreichbar und bietet eine einfache Suchfunktion: Nutzer geben eine URL ein und erhalten eine zeitliche Übersicht aller verfügbaren Snapshots. Diese Momentaufnahmen zeigen, wie eine Website zu verschiedenen Zeitpunkten aussah und funktionierte.

Kann Noah als SEO Spezialisten wärmstens empfehlen. Er weiß wovon er spricht und ist im Online Marketing zu Hause. Top Leistung!


AUSGEZEICHNETTrustindex überprüft, ob die Originalquelle der Bewertung Google ist. Lutz Online Marketing in Düsseldorf ist als SEO Freelancer tätig. Als SEO Experte arbeitet er hoch professionell, er ist sehr erfahren und in vielen Branchen tätig. Er hat mich sehr erfolgreich bei meinem Online Marketing unterstützt. Herr Lutz ist äußerst zuverlässig und sehr zielorientiert, seine Leistung war sehr schnell erfolgreich. Ich kann Lutz Online Marketing uneingeschränkt empfehlen.Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Herr Lutz hat unser Unternehmen hervorragend beraten und uns in kurzer Zeit wichtige Tipps gegeben. Vielen Dank dafür!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Sehr empfehlenswerter SEO Freelancer aus Düsseldorf! Professionell, zuverlässig und immer auf dem neuesten Stand der Entwicklungen im Bereich Suchmaschinenoptimierung. Wir Arbeiten in mehreren Projekten mit Noah zusammen und von Beginn an hat sich die Sichtbarkeit massiv verbessert. Überzeugt hat uns von Anfang vor allem auch die maximale Transparenz sowie die sofortige Erreichbarkeit bei Fragen oder Gesprächsbedarf. Das ist Dienstleistung auf einem ganz hohen Niveau. Danke für die tolle Arbeit und wir freuen uns auf alles Weitere!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Noah konnte mir gewaltig bei der Verbesserung meiner Internetpräsenz helfen! Ohne ihn war meine Seite nicht einmal indexiert, er hat sich merklich in mein Thema eingearbeitet und schnell Lösungen gefunden, die mir massiv helfen konnten. Jetzt stehe ich seit Monaten in den Top3-Ergebnissen meiner Suchbegriffe, ohne Noah wäre das nicht möglich gewesen und ich kann ihn zu 100% empfehlen! Vielen Dank für deine Ideen, deine Geduld und die tollen Ergebnisse für mein Unternehmen!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Von Anfang an war die Zusammenarbeit mit Noah Lutz eine absolute Bereicherung für unser Online-Geschäft. Als wir uns auf die Suche nach einem SEO-Spezialisten machten, um die Sichtbarkeit unserer Website in den Google-Suchergebnissen zu verbessern, stießen wir auf zahlreiche Anbieter. Die Entscheidung für Noah Lutz fiel uns jedoch leicht, sobald wir das erste Beratungsgespräch geführt hatten. Seine Professionalität, tiefgreifendes Fachwissen und die Fähigkeit, komplexe SEO-Konzepte verständlich zu erklären, haben uns sofort überzeugt. Noah Lutz hat sich die Zeit genommen, unser Geschäftsmodell und unsere Ziele gründlich zu verstehen. Er entwickelte eine maßgeschneiderte SEO-Strategie, die nicht nur auf die Verbesserung unserer Rankings abzielte, sondern auch darauf, qualitativ hochwertigen Traffic auf unsere Seite zu lenken. Durch die Implementierung gezielter Keyword-Recherchen, On-Page-Optimierung und den Aufbau einer soliden Backlink-Struktur konnten wir innerhalb weniger Monate signifikante Verbesserungen in den Suchergebnissen feststellen. Besonders beeindruckt hat uns die transparente Arbeitsweise von Noah Lutz. Er hat uns regelmäßig mit detaillierten Berichten und Analysen versorgt, die den Fortschritt unserer SEO-Maßnahmen aufzeigten. Seine proaktive Kommunikation und Bereitschaft, Fragen zu beantworten und Anpassungen vorzunehmen, wenn nötig, haben die Zusammenarbeit sehr angenehm gestaltet. Dank Noah Lutz haben wir nicht nur eine verbesserte Online-Präsenz erreicht, sondern auch ein tieferes Verständnis für die Bedeutung und Funktionsweise von SEO gewonnen. Seine Dienstleistungen haben sich als eine wertvolle Investition in die Zukunft unseres Unternehmens erwiesen. Für jedes Unternehmen, das seine Online-Sichtbarkeit ernsthaft verbessern möchte, kann ich Noah Lutz uneingeschränkt empfehlen. Seine Expertise, sein Engagement und seine Ergebnisse sprechen für sich. Wir freuen uns auf eine weiterhin erfolgreiche Zusammenarbeit.Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Wir sind äußerst zufrieden mit der knapp einjährigen Zusammenarbeit mit Noah Lutz. Seine fundierten SEO-Kenntnisse haben maßgeblich zur Stärkung der Online-Präsenz des Unternehmens beigetragen. Professionelle Zusammenarbeit, transparente Berichterstattung und nachweisliche Ergebnisse machen Herrn Lutz zu einem empfehlenswerten Partner für erfolgreiches Online-Marketing. Vielen Dank für die hervorragende Arbeit!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Super empfehlenswert! Wir arbeiten schon länger mit Herr Lutz zusammen und die Qualität sowie die Ergebnisse stimmen einfach!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Herr Lutz ist sehr kompetent, seine Erklärungen sind hilfreich, er arbeitet sehr schnell und setzt Wünsche und besprochene Maßnahmen rasch um. Das Ranking-Ergebnis für meine Webseite hat sich klar verbessert. Ich freue mich auf die weitere Zusammenarbeit.Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Deine Unterstützung war Gold wert, danke dir!Trustindex überprüft, ob die Originalquelle der Bewertung Google ist. Normalerweise setzen wir Auftrag und Erledigung in der Dienstleistung als eine ganz normale Sache voraus,aber in Ihrem Falle haben Sie mehr geleistet als abgesprochen. Genau dieses hebt Sie hervor. Vielen Dank hierfür Herr Lutz. Firma F&H Läufle GmbH
Funktionsweise und Technologie der Wayback Machine
Die technischen Grundlagen der Webarchivierung basieren auf einem ausgeklügelten System aus automatisierten Web-Crawlern und intelligenter Datenspeicherung. Das Internet Archive nutzt sowohl proprietäre als auch Quelloffene Software, um kontinuierlich das Netz zu durchsuchen und Inhalte zu erfassen.
Crawling und Archivierungsprozess
Die automatischen Webcrawler des Internet Archive arbeiten rund um die Uhr und scannen Millionen von Webseiten. Diese digitalen “Spinnen” folgen Links von Seite zu Seite, laden den html code herunter und speichern alle verfügbaren Ressourcen wie Bilder, CSS-Dateien und JavaScript-Elemente. Der Crawler respektiert dabei die robots.txt-Anweisungen der Websites, um die Wünsche der Webseitenbetreiber zu berücksichtigen.
Der Archivierung Prozess erfasst verschiedene Datei typen:
HTML-Seiten mit ihrem kompletten Quellcode
CSS-Stylesheets für das Design der Seiten
JavaScript-Dateien für interaktive Funktionen
Bilder in verschiedenen Formaten (JPEG, PNG, GIF)
PDFs und andere Dokumente
Audiodateien und Videos (soweit möglich)
Monatlich wächst das Archiv um etwa 20 Terabyte neue Daten. Die Crawler priorisieren beliebte Websites und news-Seiten, die häufiger archiviert werden als statische Unternehmensseiten. Wichtige Ereignisse oder Breaking news können zu sofortigen Archivierungen führen, um historische Momentaufnahmen zu sichern.
Die redundante Datenspeicherung erfolgt in mehreren Rechenzentren weltweit, um die Langzeitarchivierung zu gewährleisten. Das Internet Archive unterhält Standorte in San Francisco, Alexandria (Virginia) und Amsterdam, um die Daten gegen technische ausfälle und Naturkatastrophen zu schützen.
Save Page Now Funktion
Neben der automatischen Archivierung bietet die Wayback Machine die “Save page Now” Funktion, mit der Nutzer gezielt einzelne Seiten archivieren können. Diese Funktion ist besonders wertvoll für:
Wichtige Nachrichtenberichte vor ihrer möglichen Löschung
rechtliche Beweissicherung bei Streitigkeiten
Sicherung von Content vor Website-Relaunches
Dokumentation von Online-Kampagnen und deren Entwicklung
Um eine Seite manuell zu archivieren, besuchen Nutzer web.archive.org/save und geben die gewünschte URL ein. Das System erstellt innerhalb weniger Minuten einen Snapshot der Seite. Für größere URL-Listen können institutionelle Nutzer auch E-Mails an spn@archive.org senden.
Die Save page Now Funktion schließt automatisch Fehlerseiten (404-Errors) und nicht erreichbare URLs aus, um die Qualität des Archivs zu gewährleisten. Passwortgeschützte Bereiche können naturgemäß nicht archiviert werden, da die Crawler keinen Zugang zu privaten Inhalten haben.


unverbindliche Beratung
persönlicher Ansprechpartner & flexible Laufzeiten
Konkrete Analyse und Strategievorstellung nach Erstgespräch
In einem Erstgespräch haben wir die Gelegenheit, uns persönlich kennenzulernen. Dabei gebe ich Ihnen einen Einblick in meine Arbeitsweise, während ich mehr über Sie und Ihr Projekt erfahre. Im Anschluss an das Gespräch erhalten Sie ein unverbindliches Angebot, das eine konkrete Analyse und Strategievorstellung für Ihr Projekt umfasst.
Praktische Anwendungsfälle der Wayback Machine
Die vielseitigen Einsatzmöglichkeiten der Wayback Machine machen sie zu einem unverzichtbaren Tool für verschiedene Berufsgruppen und Anwendungsszenarien. Von SEO-Analysen bis zur rechtlichen Beweissicherung eröffnet das Internet Archive neue Möglichkeiten für online Recherchen und Content-Wiederherstellung.
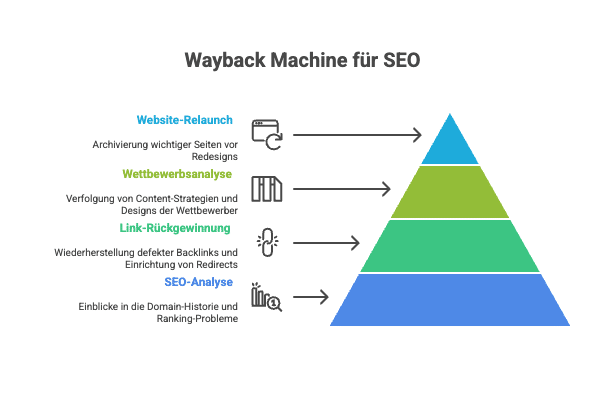
SEO und Website-Optimierung
Für SEO-Experten und Entwickler ist die Wayback Machine ein mächtiges Instrument zur Analyse und Optimierung von Websites. Sie ermöglicht Einblicke in die Geschichte einer Domain und hilft bei der Diagnose von Ranking-Problemen.
Analyse von Ranking-Verlusten: Wenn eine Website plötzlich an Sichtbarkeit in den SERPs verliert, können SEO-Experten die historischen Versionen analysieren und Änderungen identifizieren, die zu dem Verlust geführt haben könnten. Der vergleich alter und neuer html Versionen deckt oft technische Probleme oder Content-Änderungen auf.
Link-Rückgewinnung: Defekte Backlinks kosten wertvolle Link-Autorität. Mit der Wayback Machine lassen sich URLs wiederherstellen, die zu 404-Seiten führen. SEO-Spezialisten können den ursprünglichen Content einer gelöschten Seite einsehen und entsprechende Redirects einrichten oder den Content wiederherstellen.
Wettbewerbsanalyse: Die Entwicklung von Konkurrenz-Websites lässt sich über Jahre hinweg verfolgen. SEO-Experten analysieren Content-Strategien, Designs und technische Entwicklungen ihrer Wettbewerber, um eigene Strategien zu optimieren.
Website-Relaunch Unterstützung: Vor großen Redesigns archivieren Entwickler wichtige Seiten, um wertvollen Content nicht zu verlieren. Nach dem Relaunch helfen die Archive bei der Identifikation fehlender Redirects oder verschwundener Inhalte.
Nutzung der Wayback Machine: Schritt-für-Schritt-Anleitung
Die Bedienung der Wayback Machine ist intuitiv gestaltet, aber einige erweiterte Funktionen können die Effizienz bei der suche nach historischen Inhalten erheblich steigern. Diese detaillierte Anleitung zeigt, wie Nutzer das volle potenzial des Tools ausschöpfen können.
Grundlegende Suchfunktionen
Der einstieg in die Wayback Machine beginnt mit der Website web.archive.org. Die Hauptseite bietet ein übersichtliches Suchfeld, in das Nutzer die gewünschte URL eingeben. Nach der Eingabe einer domain erscheint eine Zeitlinie mit verfügbaren Snapshots, dargestellt durch kreise unterschiedlicher Größen – größere kreise zeigen umfangreichere Archivierungen an.
Die Kalenderansicht zeigt Jahre, Monate und tage mit verfügbaren Archivierungen. Blaue kreise kennzeichnen normale Captures, während grüne kreise Redirects anzeigen. Rote kreise weisen auf fehlerhafte oder unvollständige Archivierungen hin. Durch klick auf einen bestimmten Datum öffnet sich die entsprechende Version der Website.
Navigation innerhalb archivierter Seiten: Einmal in einer archivierten Version, können Nutzer normal durch die Seite navigieren. Links zu anderen Bereichen derselben Domain funktionieren meist problemlos, während externe links zu Websites führen, die möglicherweise nicht mehr existieren oder sich verändert haben.
Die Summary-Ansicht bietet eine Übersicht über alle gecrawlten Elemente einer Domain, einschließlich verschiedener Datei typen wie HTML-Seiten, Bilder, CSS-Dateien und JavaScript. Diese Übersicht hilft bei der suche nach spezifischen Inhalten oder der Einschätzung der Vollständigkeit einer Archivierung.
Erweiterte Recherche-Tools
Für professionelle Anwender bietet die Wayback Machine erweiterte tools und Schnittstellen, die komplexere Analysen ermöglichen.
Browser-Extensions: Die offizielle Wayback Machine Chrome-Extension erkennt automatisch nicht mehr verfügbare Seiten (404-errors) und bietet sofortige Umleitung zu archivierten Versionen. Diese Funktion ist besonders nützlich für SEO-Experten, die defekte Backlinks analysieren.
API-Zugang: Entwickler und forscher können über verschiedene APIs programmatischen Zugang zu den Archiv-Daten erhalten:
CDX Server API: Ermöglicht die abfrage aller verfügbaren Snapshots einer Domain
Memento API: Unterstützt zeitbasierte navigation und automatische Weiterleitung
Availability JSON API: Prüft, ob eine URL zu einem bestimmten Zeitpunkt archiviert wurde
Waybackpack-Tool: Dieses Command-Line tool ermöglicht den Massendownload aller Snapshots einer Domain für lokale Analysen. Besonders nützlich für umfangreiche Content-Audits oder akademische Forschung.
Diff-Checker Integration: Externe tools wie diffchecker.com lassen sich mit Wayback Machine URLs kombinieren, um detaillierte vergleiche zwischen verschiedenen Versionen einer Seite zu erstellen. Diese Technik deckt selbst kleine Textänderungen oder Design-Modifikationen auf.
Grenzen und Einschränkungen der Wayback Machine
Trotz ihrer beeindruckenden Leistung stößt die Wayback Machine an technische und rechtliche grenzen, die Nutzer verstehen sollten, um realistische Erwartungen an die Archivierungsqualität zu haben.
Unvollständige Archivierung
Die Komplexität moderner Websites führt oft zu unvollständigen Archivierungen, besonders bei dynamischen Inhalten und interaktiven Elementen.
JavaScript-Limitationen: Ältere Archive erfassen JavaScript-generierte Inhalte nur eingeschränkt. Single-Page-Applications (SPAs) und AJAX-basierte Websites aus den frühen 2000er Jahren sind oft nur als statische HTML-Gerüste verfügbar. Moderne Archivierungen berücksichtigen JavaScript besser, aber komplexe Interaktionen bleiben problematisch.
Externe Ressourcen: Bilder, Videos und andere Medieninhalte von externen Servern (CDNs) werden nicht immer vollständig archiviert. Wenn der ursprüngliche server offline geht, erscheinen diese Elemente als defekte links oder leere Bereiche in der archivierten Version.
Datenbank-Inhalte: Dynamische Inhalte aus Datenbanken, wie Nutzerkommentare, Suchergebnisse oder personalisierte Inhalte, können nicht archiviert werden. Die Wayback Machine erfasst nur den zum Crawling-Zeitpunkt sichtbaren zustand einer Seite.
Performance-Probleme: Große Websites mit vielen Multimedia-elementen laden in der Wayback Machine oft langsam. Zeitüberschreitungen können dazu führen, dass nur Teile einer Seite verfügbar sind.
Robots.txt und Archivierungs-Ausschluss
Website-Betreiber können die Archivierung ihrer Inhalte durch verschiedene Methoden kontrollieren oder verhindern.
Robots.txt-Respektierung: Seit April 2017 respektiert das Internet Archive robots.txt-Anweisungen weniger strikt als früher. Websites können jedoch weiterhin spezifische Anweisungen für den Internet Archive Crawler verwenden:
User-agent: ia_archiver
Disallow: /private/
Disallow: /admin/Diese Anweisung verhindert die Archivierung von privaten Bereichen und Admin-Seiten.
Vollständiger Ausschluss: Um eine komplette domain von der Archivierung auszuschließen, können Website-Besitzer folgende Zeile in ihre robots.txt einfügen:
User-agent: ia_archiver
Disallow: /Nachträgliche löschung: Bereits archivierte Inhalte können durch kontakt mit dem Internet Archive support gelöscht werden. Legitime anfragen, etwa bei Datenschutz Verletzungen oder rechtlichen Problemen, werden in der Regel berücksichtigt.
Rechtliche herausforderungen: Bei Domainwechseln oder Übertragungen des Eigentums können sich komplexe rechtliche fragen zur Kontrolle über archivierte Inhalte ergeben. Das Internet Archive navigiert diese Situationen case-by-case.
Häufig gestellte Fragen (FAQ)
Was kostet die Nutzung der Wayback Machine?
Die Wayback Machine ist vollständig kostenlos nutzbar, da das Internet Archive als gemeinnützige Organisation durch spenden finanziert wird. Es gibt keine versteckten kosten oder Premium-Funktionen – alle archivierte Inhalte stehen jedem Nutzer frei zur Verfügung. Lediglich der kommerzielle Archive-It Service für institutionelle Kunden ist kostenpflichtig.
Wie oft werden Webseiten in der Wayback Machine aktualisiert?
Die Archivierungsfrequenz variiert erheblich je nach Website-Popularität und -wichtigkeit. Große Nachrichtenseiten werden täglich oder sogar mehrmals täglich gecrawlt, während kleinere Websites nur alle paar Wochen oder Monate archiviert werden. Nutzer können durch die “Save page Now” Funktion jederzeit manuelle Snapshots erstellen.
Kann ich verhindern, dass meine Website archiviert wird?
Ja, durch Hinzufügung von “User-agent: ia_archiver Disallow: /“ in die robots.txt-datei können zukünftige Archivierungen verhindert werden. Bereits archivierte Inhalte können durch direkten kontakt mit dem Internet Archive support zur Löschung beantragt werden. Das Internet Archive respektiert legitime anfragen bezüglich Datenschutz und Urheberrecht.
Warum fehlen manche Bilder oder Funktionen in archivierten Seiten?
Technische Limitationen bei JavaScript, externe Einbindungen von CDNs und sehr große Dateigrößen können zu unvollständiger Archivierung führen. Moderne Websites mit komplexen Interaktionen sind besonders betroffen. Das Internet Archive verbessert kontinuierlich seine Crawling-Technologie, aber vollständige Funktionalität kann nicht immer gewährleistet werden.



